# Java 并发基础 CAS
文章思路:
谈谈 CAS --> 谈谈Unsafe类 --> CAS的优缺点 ---> ABA问题 --> 原子引用 --> ABA问题的规避思路
# 谈谈 CAS
CAS 即 Compare And Swap ,是保证一个共享变量的原子操作,是一条 CPU 并发原语。它判断内存某个位置的值是否为预期值,如果是则更改为新值,这个过程是原子的。
其逻辑大概如下:
- 从主存中备份旧数据 v 至 a
- 基于旧数据 a 构造新数据 b
- 比较旧数据 a 和内存中的 v
- 如果 a != v,说明有其他的线程改变过 v。那么此时跳回第一步
- 如果 a == v,那么将 v 改为 b
伪代码如下:
int a = v;
int b;
while(true) {
b = a+1;
if (a != v) {
a = v;
} else {
v = b;
break;
}
}
2
3
4
5
6
7
8
9
10
11
# 谈谈 Unsafe 类
Java 中的 CAS 操作是调用了 Unsafe 类的方法,Unsafe 类的所有方法都是 native 的。通过 Unsafe 类,我们可以直接对某个对象的某个字段的地址进行操作,更新字段的值(使用 CAS 操作去更新)。
以原子类 AtomicInteger 为例
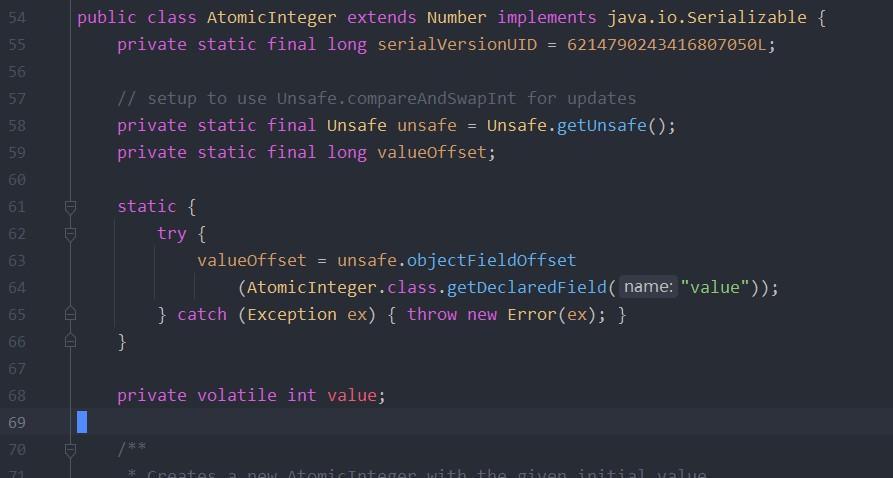
其中,static 代码块是获取 AtomicInteger 类的成员变量 value 在对象中的地址偏移量。
value 一定要用 volatile 修饰,这样某个线程对 value 的修改,其他线程能感知到,才能进行 CAS 操作。
AtomicInteger 是通过 unsafe 进行自增操作。
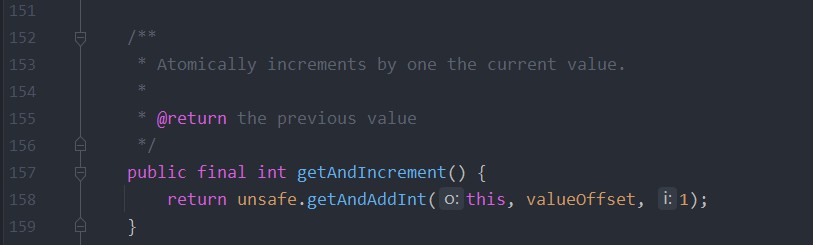
Unsafe 的 getAndIncrement 方法的代码就是获取地址的内容、更新、比较,直到预期值和地址内容一样时才会去更新地址。下面的是反编译后的代码。
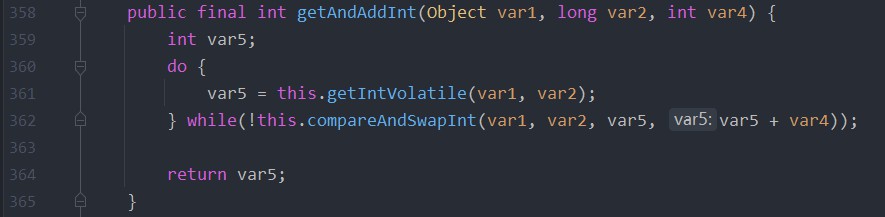
- var1 是对象本身;var2 是字段的地址偏移量;var4 是更新的目标值。
- var5 地址中的旧数据,通过 var1 和 var2 找出地址中内容。
- 用 var5 去和地址中的内容进行对比。
- 如果相同,更新 var5 + var4 并且返回 true。
- 如果不同,则继续取值然后比较,直到更新完成。
# CAS 的优缺点
循环时间长,循环开销大。
只能保证一个共享变量的原子操作。
可能存在 ABA 问题。
# ABA 问题
CAS算法实现一个重要前提需要取岀内存中某时刻的数据并在当下时刻比较并替换,那么在这个时间差会导致数据的变化。
比如说一个线程 从位置 V 中取出 A,这时候另一个线程 也从内存中取出 A,并且线程 进行了一些操作将值变成了 B,然后线程 又将位置的数据变成 A,这时候线程 进行 CAS 操作发现内存中仍然是 A,然后线程 操作成功。
尽管线程 的 CAS 操作成功,但是不代表这个过程就是没有问题的。
下面先介绍原子引用的使用。
@Data
@AllArgsConstructor
class User {
private String name;
}
public class AtomicReferenceDemo {
public static void main(String[] args) {
User u1 = new User("u1");
User u2 = new User("u2");
AtomicReference<User> reference = new AtomicReference<>();
reference.set(u1);
System.out.println(reference.get());
System.out.println(reference.compareAndSet(u1, u2) + "\t" + reference.get());
System.out.println(reference.compareAndSet(u2, u1) + "\t" + reference.get());
atomicReference();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
输出:
User(name=u1)
true User(name=u2)
true User(name=u1)
2
3
然后,我们使用原子引用模仿ABA问题的产生。
public class AtomicReferenceDemo {
public static void main(String[] args) {
atomicReference();
}
/**
* 使用普通的原子引用,依然会出现 ABA 问题
*/
private static void atomicReference() {
AtomicReference<Integer> reference = new AtomicReference<>();
reference.set(100);
new Thread(()->{
// 将变量从 100 改到 101,再从 101 改到 100,模拟ABA问题的产生
reference.compareAndSet(100, 101);
reference.compareAndSet(101, 100);
}, "AA").start();
new Thread(() -> {
try {
// 线程睡眠1秒,等待线程AA完成操作, 然后再去更新变量的值
TimeUnit.SECONDS.sleep(1);
System.out.println(Thread.currentThread().getName() + "\t"
+ reference.compareAndSet(100, 101)
+ "\t" + reference.get());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "BB").start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
输出:
BB true 101
可以看到,BB 对于 AA 的修改并不知道,然后在 BB 睡眠期间,AA 是修改过数字的。普通的原子引用无法避免 ABA 问题,那如何才能规避ABA问题呢?
在数据库中,有一种多版本控制法,给数据增加版本号,当数据发生改变之后,版本号会进行更新。当事务要进行数据更新时,持有的数据的版本号要大于记录当前的版本号才行。否则只能不断重试,直到更新完成。
而在 Java 中,有一类带戳的原子引用 AtomicStampedReference,可以实现与多版本控制法类似的效果。
public class AtomicReferenceDemo {
public static void main(String[] args) {
atomicStampedReference();
}
private static void atomicStampedReference() {
// 设置初始值 100 和初始版本号 1
AtomicStampedReference<Integer> reference = new AtomicStampedReference<>(100, 1);
new Thread(() -> {
String thread = Thread.currentThread().getName();
int stamp = reference.getStamp();
System.out.println(thread + "\t第一次版本号:" + stamp);
// 暂停一秒,让 BB 线程能拿到版本号
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 模仿 ABA 问题的产生,并更新版本号
System.out.println(thread + "\t"
+ reference.compareAndSet(100, 101, stamp, stamp + 1));
stamp = reference.getStamp();
System.out.println(thread + "\t第二次版本号:" + stamp);
System.out.println(thread + "\t"
+ reference.compareAndSet(101, 100, stamp, stamp + 1));
stamp = reference.getStamp();
System.out.println(thread + "\t第三次版本号:" + stamp);
}, "AA").start();
new Thread(() -> {
String thread = Thread.currentThread().getName();
int stamp = reference.getStamp();
System.out.println(thread + "\t第一次版本号:"+ stamp);
// 暂停3秒,让 AA 线程能拿到版本号
try {
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(thread + "\t当前版本号:" + reference.getStamp());
// 使用旧的版本号,看是否能完成更新,如果可以,那么引用的内容将变成200
boolean b = reference.compareAndSet(100, 200, stamp, stamp+1);
System.out.println(thread + "\t更换结果:" + b + "\t变量实际的最新值:" + reference.getReference());
}, "BB").start();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
输出:
AA 第一次版本号:1
BB 第一次版本号:1
AA true
AA 第二次版本号:2
AA true
AA 第三次版本号:3
BB 当前版本号:3
BB 更换结果:false 变量实际的最新值:100
2
3
4
5
6
7
8
BB 在更新之前会先判断 stamp 是否符合预期,不符合预期则不更新。
正如上面所讲,ABA 问题不仅是在 CAS 中才会出现,数据库中也有相似的问题。而解决的办法大同小异,通过一个版本号去标记数据。在 Java 中,则可以通过带版本号的原子引用来解决。
